Eine Domäne ist in Proteinen die kleinste Einheit mit einer definierten und unabhängig gefalteten Struktur. Proteindomänen bestehen meist aus 50-150 Residuen und führen häufig individuelle Reaktionen aus, deren Zusammenwirken die Gesamtfunktion eines Proteins ausmacht. Im folgenden studieren Sie zunächst ein einfaches Protein, welches aus zwei, leicht zu identifizierenden Domänen besteht. Anschließend experimentieren Sie mit einem komplexeren Proteinsystem.
Lernziel
- verstanden haben,
- seinen Einfluss auf Alignmentverfahren abschätzen können.
Ein CAP-Monomer besteht aus zwei Domänen. Die Domänengrenze ist leicht auszumachen.
- Bestimmen Sie die Positionen der Residuen, die jeweils an einer Domäne beteiligt sind.
- Bestimmen sie die Lage der Domänen im Hinblick auf ihre
Position innerhalb der Peptidkette
(N-terminal bzw. C-terminal).
| 3D-Struktur
eines CAP-Monomers Die N-terminale Domäne bindet cAMP und ist an der Dimerisierung beteiligt. Die C-terminale Domäne vermittelt die DNA-Bindung des Proteins. CAP-Dimere sind in Bakterien an der Aktivierung solcher Gene beteiligt, deren Genprodukte in den Zuckerstoffwechsel eingreifen. |
|

|
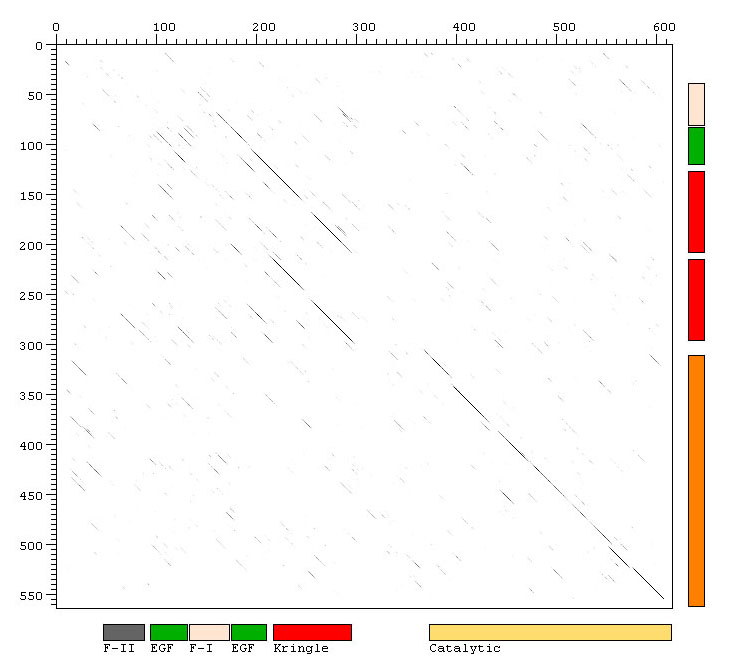
- Wie machen sich im Dotplot mehrfach in den Sequenzen vorkommende Domänen bemerkbar?
- Können Sie die Domänenstruktur der beiden Proteine bestätigen?
Übernehmen Sie aus der Datenbank SWISS-PROT (Links sind oben eingefügt) die Sequenzen und übergeben sie diese dem SMART-Server. Dazu ist zunächst der Modus Genomic auszuwählen und dann die Sequenz in das Fenster "Sequence" per cut and paste zu übertragen und die Auswertung durch Betätigen der Taste "Sequence SMART" zu starten.
- Stellen Sie unter Verwendung dieser Dotplot-Variante fest, ob
diese Proteine gemeinsame Domänen besitzen.
Starten Sie eine Dotlet-Sitzung durch Aktivierung dieses Links.
MRGLGLWLLGAMMLPAIAPSRPWALMEQYEVVLPRRLPGPRVRRALPSHLGLHPERVSYVLGATGHNFTLHLRKNRDLLG
SGYTETYTAANGSEVTEQPRGQDHCLYQGHVEGYPDSAASLSTCAGLRGFFQVGSDLHLIEPLDEGGEGGRHAVYQAEHL
LQTAGTCGVSDDSLGSLLGPRTAAVFRPRPGDSLPSRETRYVELYVVVDNAEFQMLGSEAAVRHRVLEVVNHVDKLYQKL
NFRVVLVGLEIWNSQDRFHVSPDPSVTLENLLTWQARQRTRRHLHDNVQLITGVDFTGTTVGFARVSAMCSHSSGAVNQD
HSKNPVGVACTMAHEMGHNLGMDHDENVQGCRCQERFEAGRCIMAGSIGSSFPRMFSDCSQAYLESFLERPQSVCLANAP
DLSHLVGGPVCGNLFVERGEQCDCGPPEDCRNRCCNSTTCQLAEGAQCAHGTCCQECKVKPAGELCRPKKDMCDLEEFCD
GRHPECPEDAFQENGTPCSGGYCYNGACPTLAQQCQAFWGPGGQAAEESCFSYDILPGCKASRYRADMCGVLQCKGGQQP
LGRAICIVDVCHALTTEDGTAYEPVPEGTRCGPEKVCWKGRCQDLHVYRSSNCSAQCHNHGVCNHKQECHCHAGWAPPHC
AKLLTEVHAASGSLPVLVVVVLVLLAVVLVTLAGIIVYRKARSRILSRNVAPKTTMGRSNPLFHQAASRVPAKGGAPAPS
RGPQELVPTTHPGQPARHPASSVALKRPPPAPPVTVSSPPFPVPVYTRQAPKQVIKPTFAPPVPPVKPGAGAANPGPAEG
AVGPKVALKPPIQRKQGAGAPTAP
QQNLPQRYIELVVVADRRVFMKYNSDLNIIRTRVHEIVNIINGFYRSLNIDVSLVNLEIWSGQDPLTIQSSSSNTLNSEG
LWREKVLLNKKKKDNAQLLTAIEFKCETLGKAYLNSMCNPRSSVGIVKDHSPINLLVAVTMAHELGHNLGMEHDGKDCLR
GASLCIMRPGLTPGRSYEFSDDSMGYYQKFLNQYKPQCILNKP
MAAPSRTTLMPPPFRLQLRLLILPILLLLRHDAVHAEPYSGGFGSSAVSSGGLGSVGIHIPGGGVGVITEARCPRVCSCT
GLNVDCSHRGLTSVPRKISADVERLELQGNNLTVIYETDFQRLTKLRMLQLTDNQIHTIERNSFQDLVSLERLDISNNVI
TTVGRRVFKGAQSLRSLQLDNNQITCLDEHAFKGLVELEILTLNNNNLTSLPHNIFGGLGRLRALRLSDNPFACDCHLSW
LSRFLRSATRLAPYTRCQSPSQLKGQNVADLHDQEFKCSGLTEHAPMECGAENSCPHPCRCADGIVDCREKSLTSVPVTL
PDDTTDVRLEQNFITELPPKSFSSFRRLRRIDLSNNNISRIAHDALSGLKQLTTLVLYGNKIKDLPSGVFKGLGSLRLLL
LNANEISCIRKDAFRDLHSLSLLSLYDNNIQSLANGTFDAMKSMKTVHLAKNPFICDCNLRWLADYLHKNPIETSGARCE
SPKRMHRRRIESLREEKFKCSWGELRMKLSGECRMDSDCPAMCHCEGTTVDCTGRRLKEIPRDIPLHTTELLLNDNELGR
ISSDGLFGRLPHLVKLELKRNQLTGIEPNAFEGASHIQELQLGENKIKEISNKMFLGLHQLKTLNLYDNQISCVMPGSFE
HLNSLTSLNLASNPFNCNCHLAWFAECVRKKSLNGGAARCGAPSKVRDVQIKDLPHSEFKCSSENSEGCLGDGYCPPSCT
CTGTVVACSRNQLKEIPRGIPAETSELYLESNEIEQIHYERIRHLRSLTRLDLSNNQITILSNYTFANLTKLSTLIISYN
KLQCLQRHALSGLNNLRVVSLHGNRISMLPEGSFEDLKSLTHIALGSNPLYCDCGLKWFSDWIKLDYVEPGIARCAEPEQ
MKDKLILSTPSSSFVCRGRVRNDILAKCNACFEQPCQNQAQCVALPQREYQCLCQPGYHGKHCEFMIDACYGNPCRNNAT
CTVLEEGRFSCQCAPGYTGARCETNIDDCLGEIKCQNNATCIDGVESYKCECQPGFSGEFCDTKIQFCSPEFNPCANGAK
CMDHFTHYSCDCQAGFHGTNCTDNIDDCQNHMCQNGGTCVDGINDYQCRCPDDYTGKYCEGHNMISMMYPQTSPCQNHEC
KHGVCFQPNAQGSDYLCRCHPGYTGKWCEYLTSISFVHNNSFVELEPLRTRPEANVTIVFSSAEQNGILMYDGQDAHLAV
ELFNGRIRVSYDVGNHPVSTMYSFEMVADGKYHAVELLAIKKNFTLRVDRGLARSIINEGSNDYLKLTTPMFLGGLPVDP
AQQAYKNWQIRNLTSFKGCMKEVWINHKLVDFGNAQRQQKITPGCALLEGEQQEEEDDEQDFMDETPHIKEEPVDPCLEN
KCRRGSRCVPNSNARDGYQCKCKHGQRGRYCDQGEGSTEPPTVTAASTCRKEQVREYYTENDCRSRQPLKYAKCVGGCGN
QCCAAKIVRRRKVRMVCSNNRKYIKNLDIVRKCGCTKKCY
MKSYISLFFILCVIFNKNVIKCTGESQTGNTGGGQAGNTVGDQAGSTGGSPQGSTGASQPGSSEPSNPVSSGHSVSTVSV
SQTSTSSEKQDTIQVKSALLKDYMGLKVTGPCNENFIMFLVPHIYIDVDTEDTNIELRTTLKETNNAISFESNSGSLEKK
KYVKLPSNGTTGEQGSSTGTVRGDTEPISDSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSESLPANGPDSPTVKP
PRNLQNICETGKNFKLVVYIKENTLIIKWKVYGETKDTTENNKVDVRKYLINEKETPFTSILIHAYKEHNGTNLIESKNY
ALGSDIPEKCDTLASNCFLSGNFNIEKCFQCALLVEKENKNDVCYKYLSEDIVSNFKEIKAETEDDDEDDYTEYKLTESI
DNILVKMFKTNENNDKSELIKLEEVDDSLKLELMNYCSLLKDVDTTGTLDNYGMGNEMDIFNNLKRLLIYHSEENINTLK
NKFRNAAVCLKNVDDWIVNKRGLVLPELNYDLEYFNEHLYNDKNSPEDKDNKGKGVVHVDTTLEKEDTLSYDNSDNMFCN
KEYCNRLKDENNCISNLQVEDQGNCDTSWIFASKYHLETIRCMKGYEPTKISALYVANCYKGEHKDRCDEGSSPMEFLQI
IEDYGFLPAESNYPYNYVKVGEQCPKVEDHWMNLWDNGKILHNKNEPNSLDGKGYTAYESERFHDNMDAFVKIIKTEVMN
KGSVIAYIKAENVMGYEFSGKKVQNLCGDDTADHAVNIVGYGNYVNSEGEKKSYWIVRNSWGPYWGDEGYFKVDMYGPTH
CHFNFIHSVVIFNVDLPMNNKTTKKESKIYDYYLKASPEFYHNLYFKNFNVGKKNLFSEKEDNENNKKLGNNYIIFGQDT
AGSGQSGKESNTALESAGTSNEVSERVHVYHILKHIKDGKIRMGMRKYIDTQDVNKKHSCTRSYAFNPENYEKCVNLCNV
NWKTCEEKTSPGLCLSKLDTNNECYFCYV
Übernehmen Sie jeweils per copy&paste zwei Sequenzen in die Anwendung. Vergleichen Sie auch die Sequenzen mit sich selbst, um das mehrfache Vorkommen von Domänen in einer Sequenz zu überprüfen.
Was Sie jetzt verstanden haben sollten